بررسی تاریخچه الگوریتم YOLO
درک الگوریتم تشخیص شیYOLO، مزایا، نحوه تکامل آن در طی سالهای اخیر و چند مثال کاربردی
تشخیص شی یک روش بینایی ماشین برای شناسایی و تشخیص مکان شی در یک تصویر یا ویدئو است. تشخیص مکان شی در تصویر، فرایند شناسایی مکان درست یک یا چند شی با استفاده از خطوط مرزی (bounding box) دور شی است که معمولا به شکل مستطیل دور شی مورد نظر کشیده میشود. گاهی اوقات این فرآیند با طبقهبندی تصویر یا تشخیص تصویر اشتباه گرفته میشود، که هدف آن پیشبینی کلاس یک تصویر یا یک شی در یک تصویر است. شکل زیر یک نمای کلی از تصویر خام، شی کادربندی شده و شی کادر بندی شده به همراه برچسب کلاس را نمایش میدهد.

در این پست مفهومی، ابتدا مزایای تشخیص شی، قبل از معرفی YOLO که سرآمد تمامی الگوریتمهای تشخیص شی است را درک میکنید. در بخش دوم ما بیشتر تمرکز را روی الگوریتم YOLO و نحوه کارکرد آن میگذاریم. در نهایت چندین مثال کاربردی که در آن از الگوریتم YOLO استفاده شده است معرفی میشود. در بخش آخر شیوه تکامل الگوریتم YOLO از سال 2015 تا 2024 توضیح داده خواهد شد.
YOLO چیست؟
You Only Look Once (YOLO) شما تنها یکبار نگاه میکنید. این الگوریتم سرامد الگوریتمهای تشخیص شی بیدرنگ است که در سال 2015 در این مقاله https://arxiv.org/abs/1506.02640 معرفی شد.
نویسندگان در این مقاله به مشکل تشخیص شی بصورت رگرسیون نگاه کردند تا طبقه بندی، طوریکه با خطوط مرزی جداکننده و احتمالات مرتبط با هر تصویر تشخیص داده شده توسط یک شبکه عصبی مصنوعی، این کار انجام شد. اگر شما علاقه مند به یادگیری بحث یادگیری عمیق در چارچوب پایتورچ با استفاده از زبان پایتون هستید، دوره یادگیری عمیق با پایتورچ مخصوص شماست. که این دوره شما را قادر به ساخت انواع مدلهای شبکه عصبی عمیق خواهد نمود.
چه چیزی YOLO را برای تشخیص شی مشهور نمود؟
برخی از دلایلی که چرا YOLO سرامد سایر روشها شد در زیر آمده است.
1- سرعت
2- دقت تشخیص
3- قابلیت تعمیم خوب
4- Open-source
بیایید به این موارد با جزئیات بیشتر بپردازیم.
1- سرعت:
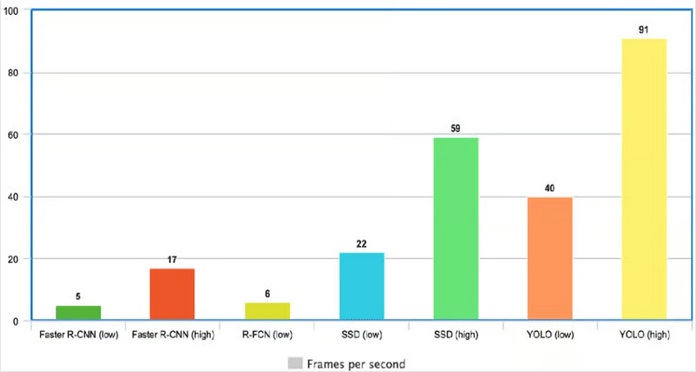
یکی از دلایلی که YOLO بسیار سریع عمل میکند این است که خود را درگیر pipeline ها نمیکند. این الگوریتم قادر به پردازش 45فریم در هر ثانیه است، بهعلاوه، YOLO به دقت میانگین دو برابری نسبت به سایر سیستمها دست یافت، که این الگوریتم را پیشگام در پردازشهای بلادرنگ نمود. از شکل زیر کاملا واضح است که YOLO با پردازش 91 فریم در ثانیه پیشگام در عمل تشخیص شی است.
2- دقت بالای تشخیص
از نظر دقت YOLO بسیار فراتر از سایر روشها که روزی سرامد بودهاند با خطای اندکی عمل کرده است.
3- تعمیمپذیری خوب
این در مورد نسخه جدید YOLO کاملا صحیح است که YOLO کاملا توانسته است در حوزههای بینایی ماشین که در ادامه بحث خواهد شد وارد شود، که مناسب نرمافزارهای کاربردی که نیازمند به پردازش سریع و دقیق در تشخیص شی هستند، میباشد. بعنوان مثال دراین مقاله نشان میدهد که اولین نسخه YOLO که با نام YOLOv1 مشهور بوده دقت میانگین کمتری در تشخیص تومور سرطانی نسبت به نسخههای YOLOV2, YOLOV3 داشته است.
4- Open-source
این مزیت منجر به تشکیل اجتماعاتی میشود تا روی بهبود نسخ مختلف کار کنند، که این تنها دلیلی است که این الگوریتم توانسته در بازه زمانی محدود رشد چشمگیری نماید.
معماری YOLO
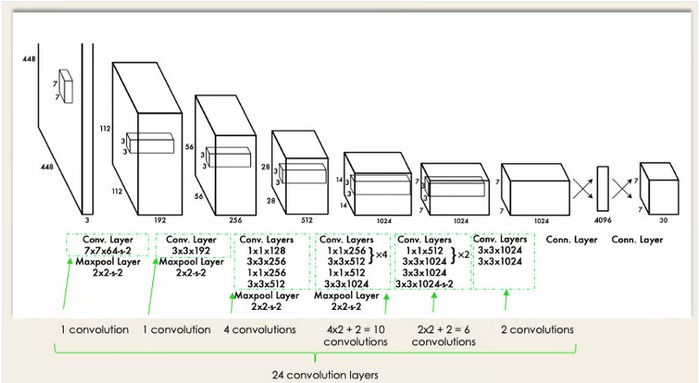
معماری YOLO بسیار شبیه به معماری GoogleNet است. همانطور که در شکل زیر نشان داده شده است، این معماری شامل 24 لایه کانولوشن، 4 لایه max-pool و دو لایه Fully-connected است.
معماری بصورت زیر کار میکند:
· تصویر ورودی به 448*448 قبل از ورود به لایه کانولوشن تغییر سایز داده میشود.
· یک کانولوشن 1×1 جهت کاهش تعداد کانالهای تصویر در ابتدا و به دنبال آن یک کانولوشن 3×3 روی تصویر جهت تولید یک خروجی مکعبی اعمال میشود.
· تابع فعالساز بهکار گرفته شده ReLU است به استثنای لایه آخر که از یک تابع فعالساز خطی استفاده میکند.
· برخی روشهای اضافهتر مانند dropout, batch normalization, regularization جهت جلوگیری از overfitting استفاده شده است.
با شرکت در دوره یادگیری عمیق توسط پایتورچ شما قادر خواهید بود که شبکههای پیچیدهتری را آموزش دهید و به دنیای هوش مصنوعی وارد شوید.
چگونه الگوریتم تشخیص شی YOLO کار میکند؟
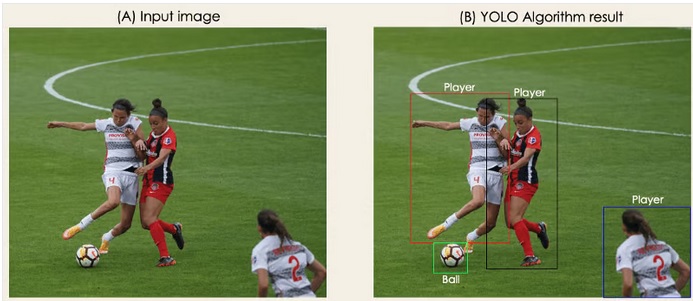
حالا که معماری YOLO را فهمیدید، بیایید یک مرور سطح بالاتری از چگونگی عملکرد الگوریتم YOLO در انجام تشخیص شی با استفاده از یک نمونه ساده داشته باشیم. یک مدل YOLO را که بازیکنان و توپ فوتبال را تشخیص میدهد را در نظر بگیرید. خوب چطور این عمل را برای افراد غیر آشنا توضیح میدهید؟ کل نکته همینجاست. شما نحوه عملکرد الگوریتم YOLO در تشخیص شی و چگونگی رسیدن به تصویر B از تصویر A را متوجه خواهید شد.
الگوریتم براساس چهار رویکرد زیر کار خواهد کرد.
Residual blocks
Bounding box regression
Intersection Over Unions or IOU for short
Non-Maximum Suppression.
بیایید نگاه عمیقتری به موضوع داشته باشیم.
Residual blocks
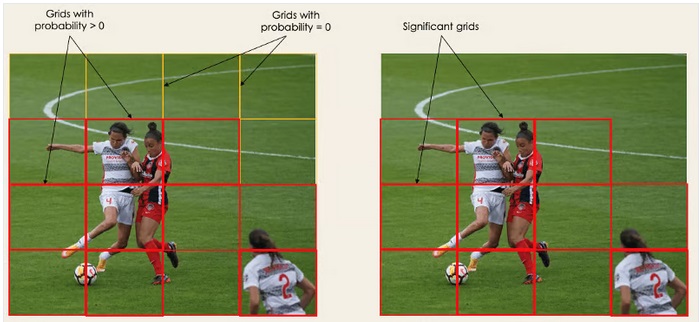
اولین مرحله با تقسیم تصویر اصلی A به یک گرید شامل تعداد NxN سلول با اندازههای مساوی شروع میشود. بطوری که N برای این مثال 4 در نظر گرفته شده است. در تصویر سمت راست می توانید مشاهده نمایید. هر سلول گرید مسئول جانمایی و تخمین کلاس شیی است که تحت پوشش آن سلول است به همراه مقدار ضریب احتمال آن کلاس.

Bounding box regression
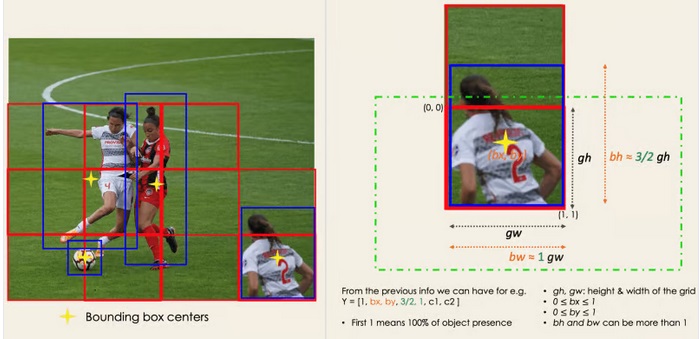
مرحله بعدی تعیین کادرهای محدود مربوط به مستطیل ها است و تمام اشیاء در تصویر را برجسته می کند. ما می توانیم به تعداد اشیاء درون یک تصویر داده شده، جعبه های محدود کننده داشته باشیم. YOLO صفات این کادرها را با استفاده از یک رگرسیون ساده همانند قالب زیر تعیین نموده طوری که Y نمایشگر بردار نهایی برای هر کادر است.
Y = [pc, bx, by, bh, bw, c1, c2]
که این بردار در فاز آموزش مدل خیلی مهم است.
Pc به امتیاز احتمال گرید شامل یک شی اشاره دارد. برای مثال تمامی گریدهای ناحیه قرمز ضریب احتمال بالاتر از صفر دارند تصویر سمت راست نسخه ساده شده است که احتمال سلولهای زرد را صفر در نظر گرفته است.
Bx و by نقاط مختصات متناظر با مرکز هر کادر به ترتیب سلول پوشاننده هستند.
Bh و bw نقاط مختصات متناظر با طول و عرض هر کادر به ترتیب سلول پوشاننده هستند.
C1و C2 متناظر با دو کلاس بازیکن و توپ هستند، ما میتوانیم به تعداد کلاسهای مورد نیاز شما مقادیر C داشته باشیم.
برای فهم بیشتر بیایید جزئی تر به بازیکن سمت راست شکل زیر نگاه بیندازیم.
Intersection Over Unions or IOU for short
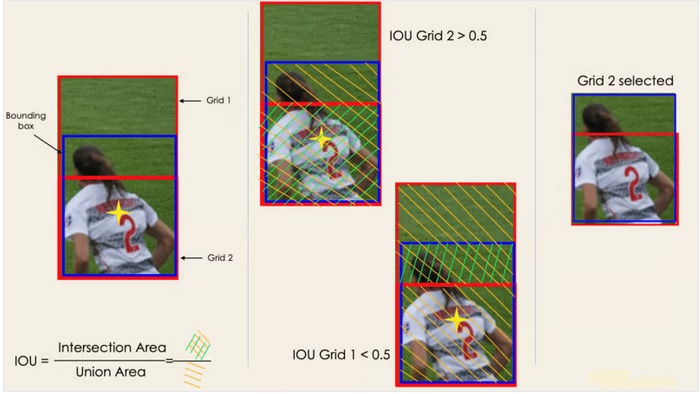
اغلب اوقات، یک شی تکی در یک تصویر میتواند گریدهای چندگانهای را برای تخمین درگیر کند. هرچند تمامی آنها مرتبط نباشند. هدف IOU (یک مقدار بین صفر و یک) حذف این سلولهای غیرمرتبط است تا سلولهای مرتبط را حفظ نماید. به منطق پشت آن در زیر اشاره شده است.
1- کاربر حد آستانه IOU را تعیین مینماید برای مثال میتواند عدد 0.5 باشد.
2- سپس YOLO مقدار IOU هر سلول گرید را محاسبه مینماید طوری که مکانهای متقاطع به Union Area تقسیم میشوند.
3- در نهایت سلولهایی که احتمال آنها از حد آستانه کمتر هستند حذف شده و فقط سلولها با حد آستانه بیشتر از 0.5 باقی می مانند.
در زیر تصویری از اعمال فرآیند انتخاب گرید بر روی شی پایین سمت چپ ارائه شده است. میتوان مشاهده کرد که شی در ابتدا دارای دو گرید کاندید بود و در پایان فقط گرید۲ انتخاب شد.
Non-Maximum Suppression.
تنظیم حد آستانه همیشه برای IOU کافی نیست زیرا یک شی می تواند کادرهای چندگانه با IOU بالاتر از حد آستانه داشته باشند که تمام آنها شامل نویز باشند. در اینجا است که ما میتوانیم از NMS برای حفظ کادرها با بالاترین امتیاز تخمین زده شده استفاده کنیم.
کاربردهای YOLO:
الگوریتم تشخیص شی YOLO کاربردهای مختلفی در زندگی روزمره ما دارد. در این بخش به برخی از حوزههای کاربردی که این الگوریتم پوشش میدهد اشاره شده است. مانند حوزه سلامت، کشاورزی، نظارتی امنیتی و خودروهای خودران
حوزه سلامت:
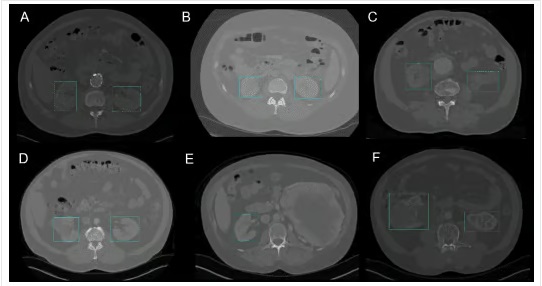
به طور خاص، در جراحی، بومی سازی اندام ها در زمان واقعی به دلیل تنوع بیولوژیکی از یک بیمار به بیمار دیگر می تواند چالش برانگیز باشد. در این مقاله برای تشخیص کلیه در CT از YOLOv3 برای تسهیل جانمایی کلیه ها به صورت دو بعدی و سه بعدی از اسکن های توموگرافی کامپیوتری (CT) استفاده شده است.
کشاورزی:
هوش مصنوعی و رباتیک نقش مهمی در کشاورزی مدرن دارند. رباتهای برداشت رباتهایی براساس دید هستند که به عنوان ابزاری جایگزین جهت چیدن میوهها و سبزیجات بصورت دستی شدهاند.
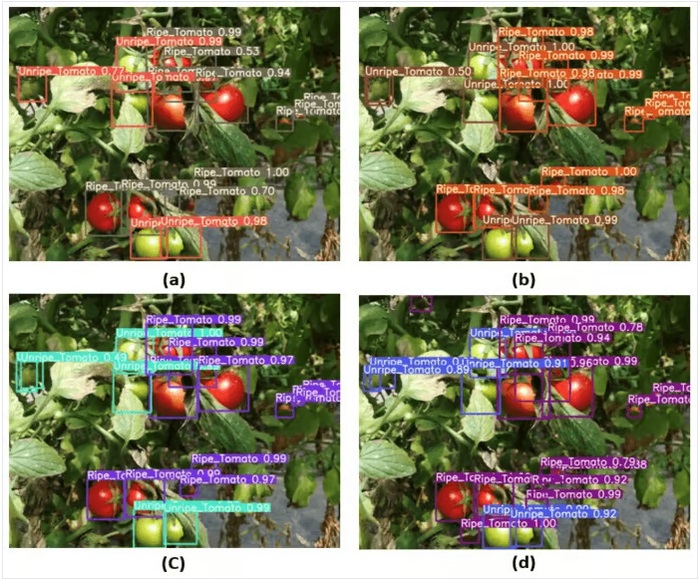
نظارتی امنیتی
اگرچه تشخیص شی اغلب در موارد نظارتی امنیتی استفاده شده است این تنها کاربرد آن نیست. YOLOv3 در طول همهگیری COVID-19 برای تخمین نقض فاصله اجتماعی بین افراد استفاده شده است.
خودروهای خودران
تشخیص شی بلادرنگ بخش DNA خودروهای خودران به حساب میاید. این یکپارچگی برای خودروهای خودران حیاتی است، زیرا آنها بایستی خطوط و تمامی اشیای اطراف و همچنین عابرین پیاده را جهت افزایش امنیت جادهای بدرستی شناسایی نماید. جنبه بلادرنگ YOLO آن را در مقایسه با رویکردهای ساده بخشبندی تصویر، نامزد بهتری می کند.
تکامل YOLO از سال 2015 تا سال 2024
از وقتی که در سال 2015 اولین نسخه YOLO منتشر شد، YOLO بعد از آن با نسخههای متفاوت بهسرعت رشد نموده است. در این بخش به جزئیات این اختلافات خواهیم پرداخت.
YOLO یا YOLOV1: نقطه شروع
این نسخه از YOLOتغییردهنده زمین بازی برای تشخیص شی بود، زیرا میتوانست خیلی سریع و کارآمد اشیا را تشخیص دهد. بااینحال، نسخه ابتدایی YOLO هم مانند دیگر نرمافزارها با محدودیتهایی مواجه بود.
· آن نسخه در حال تقلا برای تشخیص تصاویر کوچکتر درون گروهی از تصاویر بود. مانند تشخیص گروهی از افراد در استادیوم. این مشکل به این دلیل بود که در این نسخه هر گرید مختص یک شی بود.
· دوم، YOLO قادر به شناسایی اشکال غیرمعمول یا جدید نبود.
· در نهایت، تابع هزینه عادت به تخمین هزینه عملکرد تشخیص بطور یکسان برای کادرهای کوچک و بزرگ داشت که با خطاهای زیادی در جانمایی اشیا مواجه بود.
YOLOV2 یا YOLO9000
YOLOV2 در سال 2016 با ایده ساخت نسخه بهتر، سریعتر و قویتر ایجاد شد. این بهبود شامل استفاده از Darknet-19 بهعنوان معماری جدید، نرمالسازی دستهای، وضوح بالاتر ورودیها، لایههای پیچشی با لنگرها، خوشهبندی ابعاد، و (5) ویژگیهای ریز دانه است، اما محدود به آن نمیشود.
· Batch Normalization
با اضافه کردن لایه batch normalization عملکرد با 2% روی میانگین دقت(mAP) بهبود داشت. این batch normalization شامل یک اثر منظمسازی، جلوگیرنده از overfitting بود.
· Higher Input Resolution
YOLOV2 مستقیمه از رزولوشن بالاتری448×448 بجای 224×224 استفاده میکند. طوری که مدل فیلترش را جهت عملکرد بهتر روی تصاویر با رزولوشن بالاتر تنظیم میکند. این رویکرد دقت را برای آموزش دیتای ImageNet با تعداد epochs=10 تا 4% روی mAP افزایش داد.
لایههای کانولوشنی با استفاده از anchor boxes
بجای تخمین مختصات دقیق کادر دور شی مانند روشی که در YOLOV1 استفاده شد YoloV2 مشکل را با جایگزینی لایههای fully connected با anchor boxes سادهتر نمود. این رویکرد کمی دقت را کاهش داد اما recall مدل را تا 7% بهبود داد که جای بیشتری برای رشد داشت.
· Dimensionality clustering
YOLOv2 به طور خودکار anchor boxes ذکر شده قبلی را با استفاده از خوشه بندی ابعاد k-means با k=5 به جای انتخاب دستی پیدا می کند. این رویکرد جدید، تعادل خوبی بین recall و دقت مدل فراهم میکند.
برای درک بهتر خوشهبندی ابعاد k-means، نگاهی به K-Means Clustering در پایتون با آموزشهای scikit-learn و K-Means Clustering در R بیندازید. آنها به مفهوم خوشه بندی k-means با استفاده از پایتون و R می پردازند.
· Fine-grained features
پیشبینیهای YOLOv2 feature maps ۱۳×۱۳ را تولید میکنند که البته برای تشخیص اشیاء بزرگ کافی است. اما برای تشخیص اشیاء بسیار ظریف، معماری را می توان با تبدیل feature maps 26 × 26 × 512 به یک feature map 13 × 13 × 2048 که با ویژگی های اصلی الحاق شده است، تغییر داد. این رویکرد عملکرد مدل را 1٪ بهبود بخشید.
YoloV3 یک بهبود تدریجی
یک بهیود تدریجی روی YoloV2 انجام شد تا نسخه YoloV3 ساخته شد. تغییر اصلی معماری شبکه جدید (DarkNet-53) را شامل میشود. این یک شبکه عصبی 106 تایی با شبکه های UPSampling و بلوک های باقی مانده است. در مقایسه با Darknet-19، که بستر YOLOv2 است، بسیار بزرگتر، سریعتر و دقیقتر است. این معماری جدید در سطوح مختلف سودمند بوده است:
· تخمین بهتر کادر
یک مدل رگرسیون لجستیک توسط YOLOv3 برای پیشبینی امتیاز شیء برای هر جعبه محدود استفاده میشود.
· تخمین دقیقتر کلاسها
به جای استفاده از softmax همانطور که در YOLOv2 انجام شد، طبقهبندیکنندههای لجستیک مستقل برای پیشبینی دقیق کلاس کادرها معرفی شدهاند. این حتی زمانی مفید است که با دامنههای پیچیدهتر با برچسبهای همپوشانی مواجه میشوید (مانند شخص → بازیکن فوتبال). استفاده از softmax هر جعبه را محدود می کند که فقط یک کلاس داشته باشد، که همیشه درست نیست.
· تخمین دقیقتر در پیشبینی مقیاسهای متفاوت
YOLOv3 سه پیشبینی را در مقیاسهای مختلف برای هر مکان در تصویر ورودی انجام میدهد تا به Up-Sampling از لایههای قبلی کمک کند. این استراتژی به شما امکان می دهد تا اطلاعات معنایی دقیق و معنی داری را برای تصویر خروجی با کیفیت بهتر دریافت کنید.
YoloV4: سرعت بهینه و دقت در تشخیص شی
این نسخه از YOLO دارای سرعت و دقت بهینه تشخیص اشیاء در مقایسه با تمام نسخه های قبلی و دیگر الگوریتمهای پیشگام تشخیص شیء پیشرفته است. تصویر زیر عملکرد YOLOv4 را نشان می دهد که با سرعت و FPS به ترتیب 10% و 12% بر YOLOv3 غلبه کردهاست.
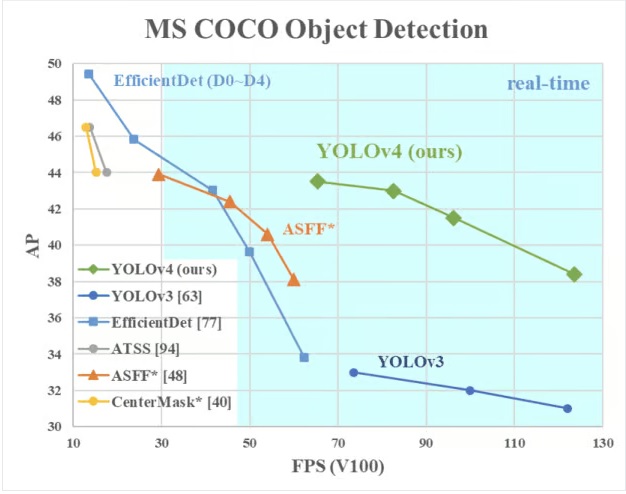
YOLOv4 به طور خاص برای سیستم های تولید طراحی شده و برای محاسبات موازی بهینه شده است. معماری بکارگرفتهشده در YOLOv4، CSPDarknet53 است، شبکه ای حاوی 29 لایه کانولوشنی با فیلترهای 3×3 و تقریباً 27.6 میلیون پارامتر. این معماری در مقایسه با YOLOv3، اطلاعات زیر را برای تشخیص بهتر شی اضافه می کند
1- بلوک ادغام هرم فضایی (SPP: Spatial Pyramid Pooling) به طور قابل توجهی میدان دریافت را افزایش می دهد، مرتبط ترین ویژگی های زمینه را جدا می کند و بر سرعت شبکه تأثیر نمی گذارد.
2- به جای شبکه هرمی ویژگی (FPN: Feature Pyramid Network) مورد استفاده در YOLOv3، YOLOv4 از PANet برای تجمیع پارامترها از سطوح تشخیص مختلف استفاده میکند.
3- تقویت داده ها از تکنیک موزاییک استفاده می کند که چهار تصویر آموزشی را علاوه بر رویکرد آموزشی خود رقیبی(یعنی با در آموزش با نسخه قبلی خود رقابت نموده تا به نسخه بهتری تبدیل شود) ترکیب می کند.
4- با استفاده از الگوریتم های ژنتیک انتخاب فراپارامتر بهینه را انجام دهید.
YOLOR : You Only Look One Representation
به عنوان یک شبکه یکپارچه برای وظایف چندگانه، YOLOR مبتنی بر شبکه یکپارچه است که ترکیبی از رویکردهای دانش صریح و ضمنی است.
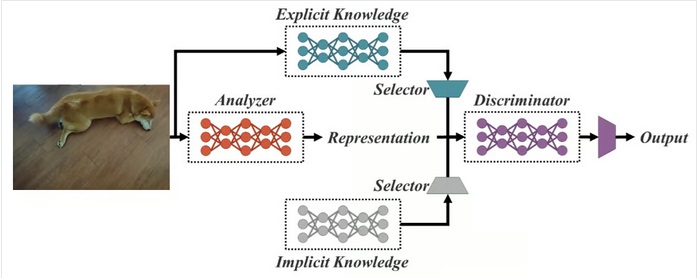
دانش ضمنی، یادگیری عادی یا آگاهانه است. از سوی دیگر، یادگیری ضمنی، یادگیری ناخودآگاه (از تجربه) است. با ترکیب این دو تکنیک، YOLOR قادر است معماری قوی تری را بر اساس سه فرآیند ایجاد کند: (1) هم ترازی ویژگی ها، (2) هم ترازی پیش بینی برای تشخیص اشیا و (3) نمایش متعارف برای یادگیری چند کار.
· همترازی تخمین
این رویکرد یک نمایش ضمنی را در feature map هر شبکه هرمی ویژگی (FPN) معرفی می کند که دقت را حدود 0.5٪ بهبود می بخشد.
· اصلاح پیش بینی برای تشخیص اشیا
پیشبینیهای مدل با افزودن نمایش صریح به لایههای خروجی شبکه اصلاح میشوند.
· نمایش متعارف برای یادگیری چند کاره
انجام آموزش چند کاره مستلزم اجرای بهینه سازی مشترک بر روی تابع ضرر مشترک در همه وظایف است. این فرآیند می تواند عملکرد کلی مدل را کاهش دهد و این موضوع را می توان با ادغام نمایش متعارف در طول آموزش مدل کاهش داد.
از نمودار زیر میتوان مشاهده کرد که YOLOR بر روی دادههای MS COCO در مقایسه با مدلهای دیگر، به سرعت استنتاج پیشرفتهای دست یافته است.
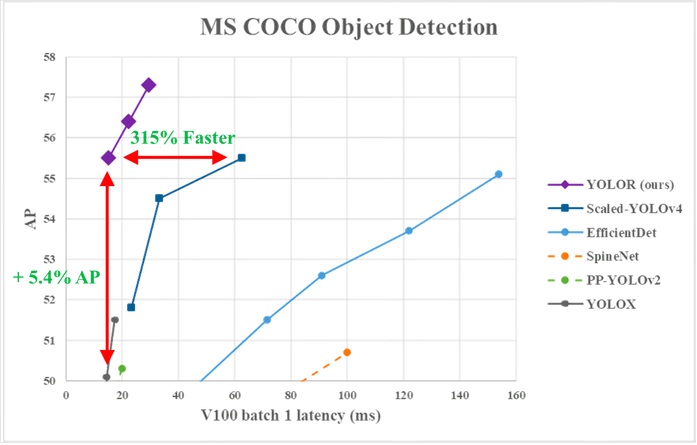
YOLOX: فراتر از انتظار سریهای مدل در 2021
این از یک خط مبنا استفاده می کند که یک نسخه اصلاح شده از YOLOv3 است و Darknet-53 به عنوان معماری پایه آن است. YOLOX که در مقاله Exceeding YOLO Series در سال 2021 منتشر شد، چهار ویژگی کلیدی زیر را برای ایجاد یک مدل بهتر در مقایسه با نسخههای قدیمیتر به جدول آورده است.
· سرجفت کارامد:
تعریف سرجفت: در شبکههای عصبی عمیق، بهویژه در مدلهای تشخیص اشیا (Object Detection)، اصطلاح Coupled Head معمولاً به معماریای اشاره دارد که در آن سر خروجی (head) شبکه شامل بخشهای وابسته به هم است.
در مدلهای تشخیص اشیا، سر خروجی معمولاً شامل دو وظیفه است: تشخیص کلاس و پیشبینی موقعیت مکانی (Bounding Box Regression).
اگر این دو وظیفه بهصورت وابسته و مشترک پردازش شوند، به آن Coupled Head میگویند.
در مقابل، اگر این وظایف بهصورت مستقل از هم پردازش شوند، به آن Decoupled Head میگویند.
سر جفت استفاده شده در نسخه های قبلی YOLO نشان داده شده است که عملکرد مدل ها را کاهش می دهد. YOLOX به جای آن از یک جدا شده استفاده می کند که امکان جداسازی وظایف طبقه بندی و بومی سازی را فراهم می کند و در نتیجه عملکرد مدل را افزایش می دهد.
· تقویت data augmentation
ادغام Mosaic و MixUp در رویکرد data augmentation به طور قابل توجهی عملکرد YOLOX را افزایش داد.
· یک سیستم anchor-free
مدلYOLOX از یک معماری Anchor-free استفاده میکند، یعنی دیگر نیازی به Anchor Boxes ندارد.
این کار باعث شد که تعداد پیشبینیها برای هر تصویر کاهش یابد و در نتیجه، پردازش سریعتر انجام شود.
از آنجایی که دیگر نیازی به محاسبه IoU (Intersection over Union) برای تعداد زیادی Anchor نیست، محاسبات سبکتر و سادهتر میشوند.
مزایای حذف Anchor در YOLOX
کاهش تعداد پیشبینیها در هر تصویر
کاهش زمان استنتاج (Inference Time)
کاهش پیچیدگی محاسباتی
بهبود کارایی مدل در کاربردهای بلادرنگ (Real-Time)
تکنیک SimOTA برای تخصیص برچسب
در اینجا بجای استفاده از رویکرد (IoU)، تکنیک SimOTA را معرفی شدهاست ، یک استراتژی تخصیص برچسب قویتر که نه تنها با کاهش زمان آموزش، بلکه با اجتناب از مسائل فراپارامتر اضافی، به نتایج پیشرفتهتری دست مییابد. علاوه بر آن، mAP تشخیص را 3٪ بهبود بخشید.
YOLOv5
YOLOv5 در مقایسه با سایر نسخه ها، مقاله تحقیقاتی منتشر شده ای ندارد و اولین نسخه از YOLO است که به جای Darknet در Pytorch پیاده سازی شده است.
YOLOv5 که توسط Glenn Jocher در ژانویه 2020 منتشر شد، مشابه YOLOv4، از CSPDarknet53 به عنوان ستون فقرات معماری خود استفاده می کند. نسخه شامل پنج مدل مختلف است: YOLOv5s (کوچکترین)، YOLOv5m، YOLOv5l و YOLOv5x (بزرگترین).
یکی از پیشرفتهای عمده در معماری YOLOv5 ادغام لایه فوکوس است که با یک لایه نشان داده میشود که با جایگزینی سه لایه اول YOLOv3 ایجاد میشود. این ادغام تعداد لایهها و تعداد پارامترها را کاهش داد و همچنین سرعت رو به جلو و عقب را بدون تأثیر عمده بر روی mAP افزایش داد.
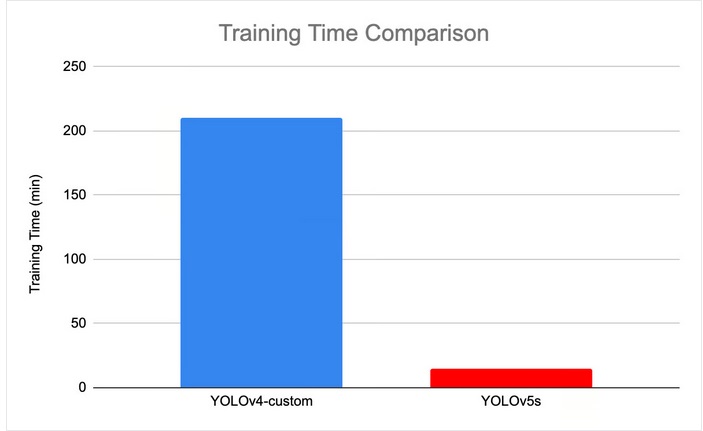
تصویر زیر زمان آموزش بین YOLOv4 و YOLOv5 را مقایسه میکند.
YOLOv6: یک چارچوب تشخیص شی تک مرحله ای برای کاربردهای صنعتی
چارچوب YOLOv6 (MT-YOLOv6) که به برنامه های صنعتی با طراحی کارآمد سخت افزاری و عملکرد بالا اختصاص دارد توسط Meituan، یک شرکت تجارت الکترونیک چینی منتشر شد. این نسخه جدید که در Pytorch نوشته شده است، بخشی از YOLO رسمی نبود، اما همچنان نام YOLOv6 را به خود اختصاص داده است، زیرا معماری پایه استفاده شده در آن از معماری اصلی یک مرحله ای YOLO الهام گرفته شده است. YOLOv6 سه پیشرفت قابل توجه را نسبت به نسخه YOLOv5 قبلی معرفی کرد: طراحی معماری پایه و سازگار با سخت افزار، سر جدا شده کارآمد و استراتژی آموزشی موثرتر.
YOLOv6 نتایج فوقالعادهای را در مقایسه با نسخههای قبلی YOLO از نظر دقت و سرعت در مجموعه داده COCO ارائه میدهد که در زیر نشان داده شده است.
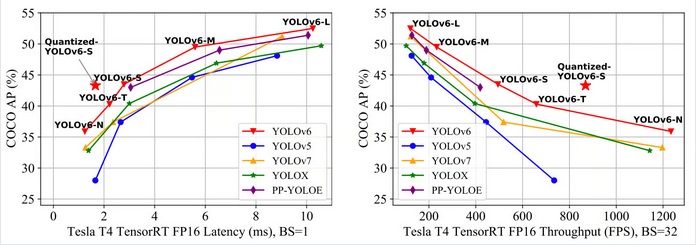
به 35.9% AP در مجموعه داده COCO با توان عملیاتی 1234 (خروجی) FPS در یک پردازنده گرافیکی NVIDIA Tesla T4 دست یافت.
YOLOv6-S به 43.3% AP جدید با سرعت 869 FPS دست یافت. YOLOv6-M و YOLOv6-L نیز به ترتیب در 49.5% و 52.3% با همان سرعت استنتاج دقت بهتری را به دست آوردند. همه این ویژگی ها YOLOv6 را به الگوریتم مناسب برای کاربردهای صنعتی تبدیل می کند.
YOLOv7: یک مجموعه قابل آموزش رایگان پیشگام جدید در تشخیصدهنده اشیا بصورت بلادرنگ
YOLOv7 در ژانویه 2022 در مقاله Trained bag-of-freebies مجموعه ای از پیشرفته ترین هنرهای جدید برای تشخیص شی بصورت بلادرنگ منتشر شد. این نسخه در زمینه تشخیص اشیا حرکت چشمگیری را انجام داد و از نظر دقت و سرعت از تمامی مدل های قبلی پیشی گرفت.
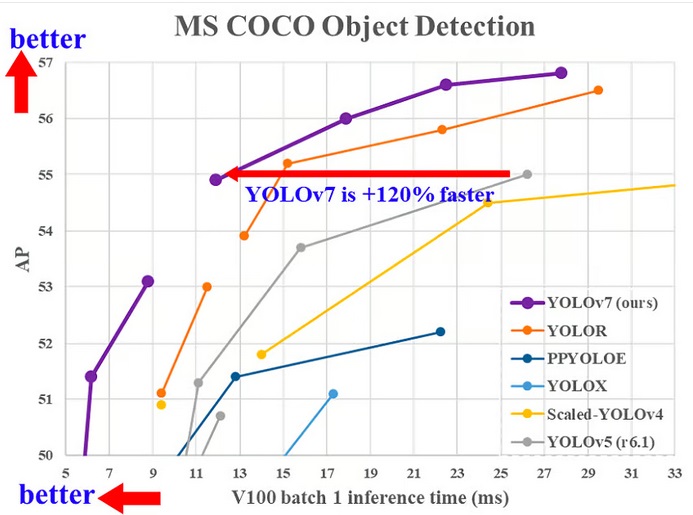
YOLOv7 یک تغییر عمده در (1) معماری و (2) در سطح مجموعه قابل آموزش رایگان ایجاد کرده است:
سطح معماری:
YOLOv7 معماری خود را با ادغام شبکه تجمع لایه کارآمد توسعه یافته (E-ELAN) اصلاح کرد که به مدل اجازه می دهد تا ویژگی های متنوع تری را برای یادگیری بهتر بیاموزد. علاوه بر این، YOLOv7 معماری خود را با الحاق معماری مدلهایی که از آن مشتق شدهاند مانند YOLOv4، Scaled YOLOv4 و YOLO-R مقیاسبندی میکند. این به مدل اجازه می دهد تا نیازهای سرعت های مختلف استنتاج را برآورده کند.
عبارت bag-of-freebies به بهبود دقت مدل بدون افزایش هزینه آموزش اشاره دارد و به همین دلیل است که YOLOv7 نه تنها سرعت استنتاج بلکه دقت تشخیص را نیز افزایش می دهد.
YOLOv8: گسترش ماژولار بودن و انعطاف پذیری
YOLOv8 یک طراحی ماژولارتر و انعطاف پذیرتر را معرفی می کند که امکان سفارشی سازی و تنظیم دقیق تر را فراهم می کند. پشتیبانی داخلی برای کارهای مختلف فراتر از تشخیص اشیا، مانند تقسیم بندی و تخمین موقعیت.
مدلهای سبک وزن، سرعت و دقت را بیشتر بهینه میکنند، با اندازههای مدلهای کوچکتر با هدف برنامههای بلادرنگ در دستگاههای لبه.
Edge Device چیست؟
Edge Device (دستگاه لبهای) به سختافزاری اطلاق میشود که در لبه شبکه قرار دارد و پردازش دادهها را نزدیک به منبع تولید داده انجام میدهد. این دستگاهها به جای ارسال دادهها به سرورهای ابری برای پردازش، تحلیل و پردازش را بهصورت محلی انجام میدهند، که باعث کاهش تأخیر و افزایش کارایی میشود.
ویژگیهای اصلی Edge Devices:
پردازش محلی دادهها → کاهش نیاز به ارسال دادهها به سرورهای ابری
کاهش تأخیر (Latency) → مناسب برای کاربردهای بلادرنگ (Real-Time)
کاهش مصرف پهنای باند → چون همه دادهها به ابر ارسال نمیشوند
افزایش امنیت و حریم خصوصی → چون پردازش در محل انجام میشود
مثالهایی از Edge Devices:
1. گوشیهای هوشمند → تشخیص چهره و پردازش صدا روی خود دستگاه (مثل Face ID اپل)
2. دوربینهای امنیتی هوشمند → پردازش تصاویر برای تشخیص حرکت بدون ارسال به سرور
3. بردهای محاسباتی کوچک مثل Raspberry Pi و NVIDIA Jetson → اجرای مدلهای هوش مصنوعی در لبه
4. روباتها و پهپادها → پردازش محیط برای تصمیمگیری سریع
5. دستگاههای IoTاینترنت اشیا
Edge Device در هوش مصنوعی و بینایی کامپیوتری
در کاربردهای بینایی کامپیوتری و یادگیری ماشین، استفاده از دستگاههای لبهای اهمیت زیادی دارد، زیرا:
· مدلهای هوش مصنوعی میتوانند مستقیماً روی دستگاه اجرا شوند (بدون نیاز به سرور ابری).
· میتوان از سختافزارهای کممصرف مانند Coral TPU، Jetson Nano یا Raspberry Pi برای پردازش استفاده کرد.
· در پروژههای بینایی کامپیوتری مثل تشخیص اشیا با YOLO، میتوان مدل را مستقیماً روی Edge Device اجرا کرد.دستگاههای Edge برای پردازش بلادرنگ، کاهش هزینههای ارسال داده و افزایش امنیت استفاده میشوند و در هوش مصنوعی، اینترنت اشیا و بینایی کامپیوتری نقش مهمی دارند.
از دیگر ویژگیهای YOLOv8 پشتیبانی از داده های سفارشی است تا به راحتی با مجموعه داده های سفارشی ادغام شود و آن را برای برنامه های خاص همه کاره می کند.
YOLOv8 همچنین API های جدیدی را برای استقرار آسان تر و مدیریت مدل در تنظیمات تولید اضافه می کند.
YOLO-NAS (Neural Architecture Search): Optimizing architecture
YOLO-NAS از جستجوی معماری عصبی (NAS) برای طراحی خودکار یک معماری بهینه شده، جهت به حداکثر رساندن عملکرد بدون تنظیم دستی استفاده می کند. این برای تعادل بهینه بین عملکرد و استفاده از منابع، مناسب برای مدلهای با دقت بالا و برنامههای با تأخیر کم طراحی شده است. این به طور خودکار وضوح را برای اشیاء مختلف در یک تصویر تنظیم می کند و روند استنتاج را بیشتر بهینه می کند.
:YOLOv9 تکنیک های پیشگامانه برای تشخیص اشیا در زمان واقعی
نسخه YOLOv9 که در سال 2024 راه اندازی شد، چندین تکنیک نوآورانه را معرفی می کند، مانند موارد زیر:
· اطلاعات گرادیان قابل برنامه ریزی (PGI): تکنیک جدیدی است که جریان گرادیان را در طول آموزش بهینه می کند و توانایی مدل را برای یادگیری کارآمدتر از مجموعه داده های پیچیده بهبود می بخشد.
· شبکه تجمیع لایه کارآمد تعمیم یافته (GELAN): یک پیشرفت معماری قابل توجه که یادگیری و تجمیع ویژگی ها را بیشتر بهبود می بخشد و به بهبود دقت و سرعت کمک می کند.
YOLOv9 معیارهای جدیدی را بر روی مجموعه داده MS COCO تنظیم می کند و عملکرد برتر را در مقایسه با نسخه های قبلی به ویژه از نظر دقت و سازگاری در کارهای مختلف نشان می دهد. اگرچه YOLOv9 توسط یک تیم منبع باز جداگانه توسعه یافته است، اما YOLOv9 بر پایه کد Ultralytics YOLOv5 ساخته شده است، که نشان دهنده تلاش مشترک در جامعه هوش مصنوعی برای پیشبرد مرزهای تشخیص اشیا است. در این نسخه پیشرفت های قابل توجهی را در فرآیند آموزش و معماری، با تمرکز بر کارایی، سازگاری و دقت برای کاربردهای بلادرنگ نشان می دهد.
نتیجهگیری:
این مقاله مزایای YOLO را در مقایسه با سایر الگوریتمهای پیشرفته تشخیص اشیاء و تکامل آن از 2015 تا 2020 با برجستهترین مزایای آن پوشش داده است. با توجه به پیشرفت سریع YOLO، شکی نیست که برای مدت طولانی در زمینه تشخیص اشیا پیشرو باقی خواهد ماند. گام بعدی این مقاله استفاده از الگوریتم YOLO در موارد واقعی خواهد بود. تا آن زمان، دوره_مقدماتی_یادگیری_عمیق_با_پایتورچ که در آکادمی هوش مصنوعی کامبیز طباطبائی ارائه شده است میتواند به شما در یادگیری اصول شبکههای عصبی و نحوه ساخت مدلهای هوش مصنوعی در پایتون کمک کند.
دیدگاهتان را بنویسید